Milyon yenlik soru

Görsel romanlar ve diğer birtakım Japonca programlarla haşır neşir olmaya başladığım ilk günlerde, Japonca karakterleri doğru düzgün görüntüleyebilmek için AppLocale adlı yardımcı uygulamayı kullanıyordum. Lakin bu uygulama zamanla ihtiyaçlarımı karşılamamaya başladı ve yaşadığım muhtelif sorunların ardından işletim sistemimin yerel ayarını Japonca olarak değiştirmeye karar verdim.
Bugün, yaklaşık altı aydır bilgisayarımı bu şekilde kullanıyorum. Halimden memnunum. Ama izninizle hem biraz şikâyet edecek, hem de neden şikâyet etmememiz gerektiğini anlatacağım. Nedenini değil nasılını merak ediyorsanız, öncelikle gorselroman.net için hazırladığım Japonca Programları Düzgün Çalıştırma Rehberi’ne bir göz atabilirsiniz.

Soldaki resimde -baykuş hariç- tuhaf bir şey görüyor musunuz? Normalde dizin ayracı olarak kullanılan ters eğik çizgi karakteri, gözlerimiz bir büyüyle bağlanmadıysa eğer, yerini her nasılsa Yen sembolüne bırakmış.
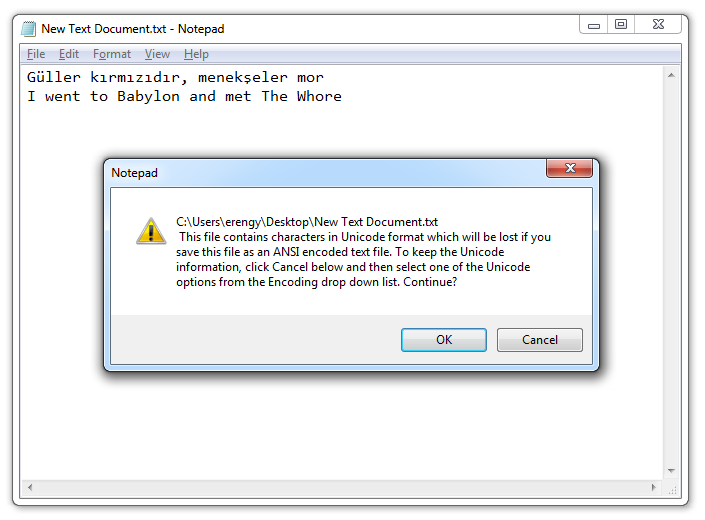
Notepad’i açıyor, aklıma düşenleri not alıp kaydetmeye çalışıyorum. Ama o da ne? Bu metni normal yollardan kaydedersem, içerisindeki bazı karakterlerin kaybolacağını söylüyor Windows bana. Kendi bildiğimi okuyor, dosyayı kapatıp tekrar açtığımda içindeki Türkçe karakterleri bir daha okuyamıyorum.
Harf dediğin nedir?
Bilgisayarlar söz konusu olduğunda harflerin pek bir anlamı yok. Harf demek, sayı demek. Siz bilgisayarınızda bir şeyler yazıp kaydettiğinizde, sabit diskinizde harfler değil, o harflere karşılık gelen rakamsal değerler saklanıyor. Aynı şey noktalama işaretleri ve hatta “görünmez” karakterler için de geçerli. Mesela siz klavyenizden Enter tuşuna bastığınızda, işletim sisteminiz veya kullandığınız program oraya satır atlamaya yarayan görünmez bir karakter (Windows ortamında iki karakter) daha ekliyor aslında.
Teknik detaylara girmeden önce, güzel bir benzeşim kurmak adına yazı tiplerini düşünelim. Aynı harfleri farklı yazı tipleri seçerek farklı biçimlerde görüntüleyebiliyoruz bildiğiniz üzere. Hatta örneğin Webdings ya da Wingdings ailesinden bir yazı tipi seçmeyi denediyseniz daha önce, harfler yerine çok daha değişik işaretler de görüntüleyebildiğimizi fark etmişinizdir.
Şimdi deney olarak, hepimizin aşina olduğu bir konum ifadesini sitenin varsayılan yazı tipiyle yazıyorum:
C:\Program Files\
Sorun yok, devam ediyorum. Sırada aynısını MS UI Gothic yazı tipiyle görüntülemek var:
C:\Program Files\
Ters eğik çizgi, sihirli bir şekilde Yen sembolüne dönüştü! Aslında hiçbir şey hiçbir şeye dönüşmedi, sadece 0x5C numaralı karakter artık farklı görünüyor. İnanmazsanız kopyalayıp Notepad’e yapıştırmayı deneyin; orada yine ters eğik çizgi şeklinde çıkacaktır. Windows’un sistem yerel ayarını Japonca olarak değiştirdiğinizde fark edeceğiniz üzere, kurulum ekranlarında ve DOS penceresi gibi yerlerde de dizin ayracı olarak ters eğik çizgi yerine Yen sembolü görüntüleniyor. “Japonlar yapmış!” demeye alışkın olan biz, bu kez sormadan edemiyoruz: “Japonlar bunu neden yapmış?”
Ters eğik çizgi yerine Yen sembolünün kullanımı Japonlar tarafından ta 1969 yılında kabul edilen ilk karakter dizisine kadar uzanıyor. Aynı durum Korece sistemlerde bu kez Yen yerine Won sembolü (₩) olarak karşımıza çıkıyor. Paraya düşkün olduklarından değil, ellerindeki tüm sembolleri kısıtlı alana sığdırma gereksinimlerinden ortaya çıkmış bir durum bu. Gel zaman git zaman, kullanılan standartlar değişiyor ama alışkanlıklar değişmiyor. Az önceki deneyde elde ettiğimiz sonuç da aslında alışkanlıkları değiştirmemek, daha doğrusu alışkanlıklarını değiştirmek istemeyenlerin asabını bozmamak adına yapılan tercihlerin bir ürünü.
Bir harf bazen başka bir harftir
Türkçe karakter bakımından zengin olan AĞAÇ kelimesini ele alalım. Her bir harfi rakamsal karşılığıyla yazacak olursak, bu kelimeyi alıştığımız sayı sisteminde 65 208 65 199, 16 tabanlı sayı sistemindeyse 41 D0 41 C7 olarak ifade edebiliyoruz. Bilgisayarımız da kendi anladığı dil ile bizimki arasında sürekli bu tarz dönüşümler yapıyor. Sorun şu ki biz bilgisayarımız Türkçe konuşsun isterken, bir başkası için bu dil Japonca, Rusça ya da Yunanca olabiliyor. Günümüz şartlarında az evvel bahsettiğim dönüşüm sıradan bir işlem gibi görünse de, uzun yıllar önce, son derece yakın bir galakside, bu amaçla oluşturulmuş evrensel bir çözüm yoktu ortada.
Her harfin bir rakamsal karşılığı var dedik ya; elinizdeki bütün harfleri, noktalama işaretlerini ve benzeri karakterleri 0-255 arası sayılardan oluşan bir tabloya sığdırmanız gerekiyordu eski günlerde. Her ülke kendi karakter yerleşimini oluşturdu ve bunlar kod sayfaları olarak isimlendirildi. 0-127 arası sayılara karşılık gelen işaretler, az önce bahsettiğim Yen sembolü gibi bazı istisnalar hariç, her kod sayfası için aynı. 128-255 arasındakilerse sayfadan sayfaya değişiyor ve çoğunlukla o dile ait özel harfleri saklamak için kullanılıyor.
Windows-1254 adlı Türkçe kod sayfasında 0xD0 değeri Ğ harfine, 0xC7 değeriyse Ç harfine karşılık geliyor. Aynı değerlere Shift-JIS için baktığımızda görüyoruz ki 0xA1-0xDF arası değerlerde katakana var! 0xD0 değeri bu sefer ミ harfine, 0xC7 değeriyse ヌ harfine karşılık geliyor.
Meraklısına not: “0x” ifadesi, başına eklendiği sayının 16 tabanlı olduğunu gösteriyor ve 10’luk sistemle karışmaması için kullanılıyor.
Şimdi sevgili ağacımıza geri dönelim:
0x41 0xD0 0x41 0xC7
Windows-1254 A Ğ A Ç
Shift-JIS A ミ A ヌ
Tebrikler! En azından artık bazı uygulamalarda “Fıstıkçı Şahap” yazdığınızda neden “Fýstýkçý Þahap” olarak göründüğünü biliyorsunuz!
Bir harf dünyaya bedeldir
Yazıyı daha fazla uzatmak istemiyorum ama tüm bu sorunlara evrensel bir çözüm getiren Unicode’dan bahsetmesek olmaz. Unicode düzeninde, hangi dile ait olursa olsun, her karakterin yalnızca kendine ait bir rakamsal değeri var. Dolayısıyla tüm karakterler her türlü koşul altında düzgün görüntülenebiliyor. Yani, sayılır. Bu kez sayısal değerleri harflere dönüştürmek için sistem yerel ayarı gibi bir değişkene ihtiyaç duymuyoruz, ama ilgili metnin hangi kodlama (örneğin UTF-8) kullanılarak kaydedildiğini bilmemiz gerekiyor.
Web sayfaları için:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
XML dosyaları için:
<?xml version="1.0" encoding="UTF-8" ?>
Metin dosyaları için, en başa eklenen byte order mark (BOM):
0xEF 0xBB 0xBF
…ilgili metnin Unicode olduğuna ve UTF-8 ile kodlandığına işaret ediyor.
İdeal bir dünyada, bütün uygulama geliştiricilerinin artık uygulamalarını Unicode’a geçirmeleri gerekirdi; ama gördüğünüz üzere henüz bu ideale tam anlamıyla ulaşabilmiş değiliz. Diğer yandan artık geliştirilmeyen uygulamaları da düzgün bir biçimde çalıştırmak işletim sisteminin sorumluluğunda ve bu sebepten ötürü, geriye uyumluluğu elden bırakmamak adına, Windows kendi içinde Unicode üzerinden çalışsa bile programların tercihlerine saygı duymak zorunda. Biz kullanıcılarsa geçmişin zincirlerinden ve Unicode olmayan programlardan tamamen kurtulana dek, sistem yerel ayarına ve bu ayarı “-mış gibi” yapan AppLocale türevi uygulamalara bağımlıyız. Şikâyet etmek serbest, ama faydasız.